
NOTE: This website is an archived copy of Al Bregman's personal website, created with the permission of Abigail Sibley and Christopher Lyons. Copyright (c) 2008 Al Bregman.
Is ASA innate?
Given the value of auditory scene analysis (ASA) to the perceiver, one would imagine that the capacity to hear acoustic input as a mixture of separate sources of sound would have evolved as part of the sense of hearing. While it is conceivable that somehow each individual infant learns the rules by which this sound separation can be accomplished, animals are, generally speaking, innately equipped to deal with the features that are typically possessed by the type of environment that the species lives in (such as the smell of the typical food of the species), while leaving to the learning process those features of the environment that differ from one individual to the next (such as the specific locations of food sources).
By this line of reasoning, one would expect that the processes of auditory grouping that depend on fairly universal properties of sounds (such as the fact that the frequency components of a single sound tend to start and end together) would be the product of inborn processes, whereas the properties of sounds that are specific to the environments of individual animals (such as those that define one’s mother’s voice) would be expected to be acquired by learning.
Investigating the “innateness” hypothesis
There are a number of lines of investigation that bear on the question of innateness of the perceptual mechanisms underlying ASA.
The first is whether very young human infants show evidence of ASA in their hearing. If ASA is innate, the answer should be "yes'. This question is difficult to investigate by experiments because very young infants have few ways of showing the effects of ASA on their behavior. For this reason, I will describe physiological techniques for detecting the presence of ASA in the hearing of adults, and then describe how these techniques have been harnessed to detect the presence of segregated auditory streams.
A second line of investigation is the study of ASA in a variety of types of animals. If it is widespread among animals, one can surmise that it is an innate part of the sense of hearing. I will mention studies of mammals, birds, fish, and amphibians.
ASA has indeed been found in many non-human animals, and this has made possible a third line of investigation: the study of the brain processes that underlie ASA. I will describe observations made in the auditory cortex of animals as their brains carry out ASA. Let me begin by describing the research on human beings.
Physiological research on humans
Event related potential (ERP) and Mismatch negativity (MMN)
There are certain questions about ASA that are hard to study with behavioural methods. One is whether or not attention is necessary for the segregation of one sound from another. We know that attention can be involved (as when we are "trying" to hear one of the sounds in a mixture). But does it always have to be involved or can perceptual organization occur in the absence of attention? Although this question is important, as soon as we ask listeners to report on what they are hearing, their attention is engaged. This makes it hard (though not impossible) to study organization in the absence of attention. One approach to overcoming this difficulty is to employ neurological measures of perceptual organization, which are not voluntarily controllable by the listener.
A second question that is hard to investigate by behavioural methods is whether very young infants organize the sounds that they hear into auditory streams. The problem is that they have a very limited number of behaviours that a researcher could use as an index to their perceptual organization. Neurological methods have been helpful in addressing this question.
One approach involves measuring the electrical activity of the brain, recorded by electrodes pasted to the scalp of the listener. From such a recording, researchers can derive what is called an event-related potential (ERP). The latter is the characteristic electrical pattern evoked by a specific type of external event, such as a type of sound. [While it can be evoked by stimuli other than sounds, I will focus the present discussion on sounds.]
The ERP is derived by playing a sound (or class of sound) occasionally to a listener and recording the electrical response of the brain to each presentation. Even with a single listener and a single type of sound, each such recording will be different, because of other events happening both outside and inside the listener. However if many such event-related recordings are averaged (aligning them by their temporal relation to the onsets of the sounds) we will be able to see the typical pattern evoked by that type of sound.
An example of the use of the ERP to study auditory organization comes from the work of Claude Alain and his colleagues at the Rotman Research Institute in Toronto on the neural activity associated with the perceptual decomposition of an incoming spectrum into separate concurrent sounds. Some of this research is based on the fact that the ASA system tends to "fuse" concurrent frequency components (partials) into a single sound if they are all multiples of the same fundamental frequency, f, (i.e., if they are harmonics of f).
If all the partials except one for one (which we will label as p) are harmonics of f, these harmonics will be integrated into a sound with the pitch of f. The "mistuned" partial, p, which is not a harmonic of f, will be heard as a separate sound with its own pitch. Hence two pitches, f and p, will be heard at the same time. The segregation of these two sounds will increase in proportion to the deviation of p from a frequency that is a multiple of f. For example, 100, 200, 300, 400 and 500 Hz are all multiples of 100 Hz (f) and will fuse into a single rich sound with the pitch of f. If the 300-Hz component is gradually raised in frequency from 300 to 345 Hz, the listener will increasingly hear it as a separate sound.
Alain and his colleagues found that a spectrum in which only one sound, f, was heard evoked an ERP that was different from the one in which two sounds, f and p, were heard. In particular, the latter ERP contained a distinctive wave component. It had an earlier negative part (called "object-related negativity" or ORN) which was present whether the listener was actively listening to the sound or was watching a silent movie. It also had a later positive part which was present only when the listener was actively listening to the sound. These results were deemed to be consistent with a two-stage model of auditory scene analysis in which the acoustic wave is first automatically decomposed into perceptual groups (the process indexed by the ORN) and then later identified by higher executive functions (indexed by the positive wave).
The studies by Alain and his colleagues have focused on the integration of simultaneous components, but there has also been research on the integration of components in a sequence. For a number of years, I have been collaborating with Elyse S. Sussman and her colleagues at Albert Einstein College of Medicine using ERP’s to look at auditory stream segregation.
Let me explain what "mismatch negativity" is: If a listener hears a sequence of sounds that all have the same value of some feature (for example, they all have the same loudness) and then one occurs that is deviant with respect to that feature (say it is less loud), the ERP measured for the deviant sound will show a negative wave component called "mismatch negativity". This appears to be a neural response to change. The feature whose change evokes MMN can take many forms, e.g., pitch, amplitude, and timbre.
Sussman’s method uses the MMN evoked by the changes in a pattern of sounds. One can evoke MMN not only by changing a property of a single repeating sound, but also by first presenting a short sequence of sounds, over and over again, and then suddenly changing the order of those same sounds. So the system whose activity we measure by MMN can learn a pattern and respond when it changes.
But the repeating pattern has to be short. If it is too long, the MMN system won’t be able to remember it well enough to recognize a change. It is this inability to memorize long sequences that allows us to study the formation of auditory streams.
Here’s how it works. Suppose a person is presented with a six-tone pattern, involving 3 different tones in each of two different frequency ranges. Let’s call the high tones H1, H2, and H3, and the low ones L1, L2, and L3.
The tones from the two ranges registers might be interleaved in the order, H1,L1,H2,L2,H3,L3,… repeated over and over in a repeating cycle of alternating high and low tones. As the brain "gets used" to this pattern the MMN responses will disappear. Suppose that, without a break, we then change the order of the tones to H1,L1,H3,L3,H2,L2…. There is still an alternation of high and low tones but the order has changed, both for the sequence as a whole, and for the high and low tones viewed as separate sub-sequences.
If the listener is hearing all the tones in a single stream, then we can say that the order of tones in a six-tone sequence has changed. But a six-tone sequence is too long for the MMN system to memorize; so it will not detect the change, and no MMN will be seen right after the change.
On the other hand if the listener is hearing the sequence as a high stream accompanied by a low stream, each containing 3 tones, the high stream has changed from H1,-,H2,-,H3,-,… to a new order, H1,-,H3,-,H2,-,… (where the hyphens represent the temporal gaps caused by the fact that the low tones are in a separate stream). Similarly the low stream has been changed from L1,-,L2,-,L3,-, to L1,-,L3,-,L2,-,…. In each case the order of a three-tone sequence has changed. A sequence of three tones is short enough to be remembered by the MMN system; so an MMN wave will be found in the ERP, right after the change.
Taken together, these facts allow the researcher to decide whether the listener was hearing one stream or two. If the change fails to evoke an MMN, then only one integrated sequence must have been heard; if MMN is evoked by the change, there must have been two streams.
Further research has shown that, when streams are segregated, a change in either of the two streams (high or low) will evoke an MMN. It looks as if the MMN system can keep track of two or more simple sequences at once, though it can’t deal with a complicated sequence.
Research using the MMN measure has given interesting results:
- At least three frequency-based streams can be present at the same time, and a change in any of them will trigger the MMN response.
- Streams will form even when attention is engaged elsewhere; so attention is not required for stream segregation
- Attention to one of the frequency-based streams strengthens the MMN response to changes in that stream. However, it is not clear whether (a) attention increases the perceptual segregation of the attended-to stream, or (b) attention simply makes the MMN system more acute at noticing changes (there is some indication that this is the correct interpretation).
MMN Research on infants
One would think that infants should be innately equipped with the ability to partition their sensory input into distinct sounds. This would kick-start the learning process, allowing babies to learn the properties of distinct auditory events – an impact, a voice, a creak in the cradle – rather than having to deal with a mish-mash of unorganized sound. However, the number of studies that have looked at auditory organization in infants has not been large, and they have mostly been done on older infants. So a critic of the hypothesis that ASA is innate might argue that these children were old enough to have already acquired organizational principles through experience. For example, experience with rich tones, such as voices, might teach a young brain that the harmonics of a tone (tones whose frequencies are multiples of the same low frequency) tend to occur together. This would be a basis for treating them as parts of a single sound when encountered in the future. So I want to skip most of the research and focus on a study that examined the auditory organization of infants that were only a few days old.
István Winkler of the Hungarian Academy of Sciences and his collaborators (Elyse Sussman, Risto Näätänen, and others) played sequences of sounds to newborn infants who were only 2 to 5 days old while they were in a period of active sleep. They measured auditory organization using a method related to Sussman’s. The following figure summarizes their experiment.
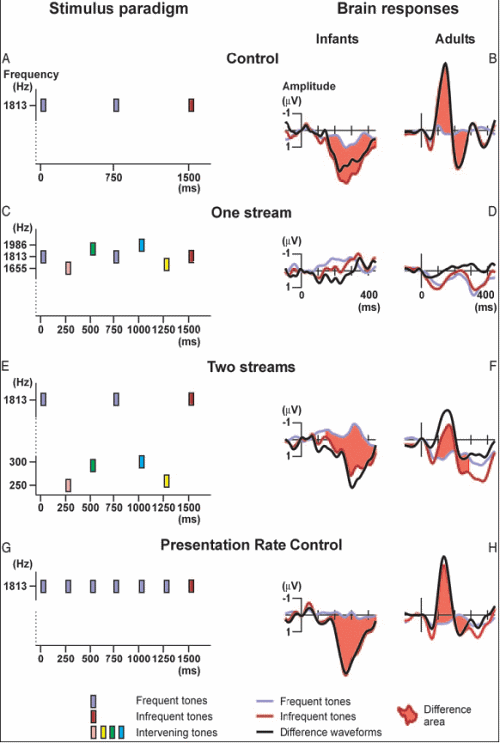
- In Condition 1 (panel A of the figure), they presented the babies with a sequence of tones that were all the same, except for a small percentage of them ("infrequent tones") which were raised in intensity (loudness). Accordingly, there would be many parts of the sequence in which a sequence of identical tones was followed by one that was more intense (a "deviant", colored orange in the figure). The ERP of the babies to the deviant tone showed a response to the change, but it was in the positive direction, unlike the negative-direction MMN response of adults. [Note that in the figure, the direction "up" is considered negative and "down" is positive – don't ask me why!] Yet the brain response to the change was clear-cut for the infants. So the fact that it was in the positive direction was not deemed important for the purposes of the experiment.
- In Condition 2 (panel C), the tones always changed in loudness and frequency from one tone to the next; so no expectation of a particular loudness was built up and no "change" response was observable in the ERP when the "deviant" (colored orange) was presented (it wasn't really deviant from any built-up expectation).
- Condition 3 (panel E) was the critical one. In it, the tones occurred in two frequency ranges. In one range (say the higher one), a few tones of increased intensity were scattered among a large majority of tones of a lower, fixed intensity, as in Condition 1; so at various points in the sequence, several tones of the same intensity were followed by a deviant of increased intensity. But unlike the case of Condition 1, other tones, in the lower-frequency range, were inserted in the temporal gaps between the tones of the high sequence. These lower-frequency tones varied in loudness, as in Condition 2. In effect, Condition 3 consisted of Condition 1 interleaved with Condition 2.
If the babies treated all the tones as forming a single sequence, then the "change" response of their brains to the deviant should not occur, since the tones (taken as a single group) were continually changing in intensity; so the deviant would be nothing special. On the other hand, if they segregated the two streams and responded to each separately, their ERPs should show a "change" response whenever the deviant in the higher stream occurred.
The results (in the right-hand panels of the figure) showed that there was indeed a strong response to a deviant occurring in the higher-frequency stream of Condition 3, indicating that stream segregation had occurred as a result of the frequency separation between the high and low tones. This supports the idea that at least some of the mechanisms of auditory scene analysis are present at birth, and are able to serve as a foundation for the early learning about the important sounds in the infant’s environment. It also supports the idea that stream segregation can take place without attention, since the babies were asleep (in "active sleep") during this experiment.
Research on non-human animals
Behavioral measures of ASA
A process of auditory scene analysis has to be part of the auditory systems of non-human animals, no less than those of humans. All animals face the problem of dividing their auditory input into sounds coming from distinct sound sources in order to find mates, escape predators, or catch prey. So it is likely that many of the mechanisms of ASA evolved fairly early in the evolutionary history of vertebrates.
Richard R. Fay put it this way in his 2007 review of ASA in nonhuman vertebrates:
"… an auditory system could not have been an advantage to any organism (i.e., could not have evolved among all vertebrate species) had it not had the primitive (shared) capacity for sound source perception from the start. In other words, if the sensory evidence obtained by our (ancestors’) senses were not untangled and assigned to one or another auditory object or event, the sensory evidence itself would be all but useless, and could not contribute to fitness".This view is, perhaps, a bit extreme. However, if we believe that evolution tends to be incremental, there is no doubt about the central role that processes analogous to ASA must play in the hearing sense of non-human animals.
Research on ASA in animals has used two methods. One is to show that they can pick out sounds that are important to them from the acoustic environment in which they are normally embedded. The other is to set up laboratory experiments to study the process. Both methods have demonstrated ASA in non-human animals.
Natural sounds
Here is an example of a study using natural sounds. It has been observed that the infants of animals that live in groups, such as penguins, can find their own parents by perceptually segregating the latter's calls from the calls of other parents. In 1998, the researchers, Thierry Aubin and Pierre Jouventin, followed up this observation with tests in which the recorded calls of king penguins were played to chicks. These tests found that chicks can detect their parent’s call even when it is mixed with the calls of five other adults, where the mixture of the other parents’ calls was 6 dB more intense than the calls of the chick's own parents
The work of the late Stewart Hulse and others has shown that songbirds can correctly recognize the songs of a particular species and of particular individuals when these songs are digitally mixed with the songs of other species or individuals and even when they are mixed with the sounds of a dawn chorus (studied by Stewart H. Hulse, Scott A. MacDougall-Shackleton, and Amy B. Wisniewski in 1997; and by Wisniewski and Hulse in 1997).
Starlings
The 1997 study by Hulse, MacDougall-Shackleton, and Wisniewski also trained European starlings, using operant conditioning methods, to peck for food. They were presented with a 10-second sample of a mixture of two bird songs, and trained to peck only when one of the two songs was from a starling. There were 15 unique examples containing a starling, and 15 that did not. They learned to discriminate the two types of mixture with 85 percent accuracy, Yet the question arises: was this really ASA, or did the starlings simply memorize the starling-containing mixtures as wholes? To examine this possibility, the researchers tested the starlings on brand new samples of the two types of mixture. Without any further training the starlings could immediately pick out the starling-containing mixtures. They also – again without further training – responded positively (with greater-than-chance probability) when the starling song was presented alone. These results led the researchers to conclude that the birds did not merely memorize the starling-containing mixtures, but could segregate the two signals that were in the mixture.
However there is another possibility: The starling signal probably has some unique features that survive mixing, and the birds may have merely responded to these features whenever they were detected in a perceptually undifferentiated mixture. In some sense, this would still have been a form of ASA, because the birds could still detect the presence of a meaningful call in a mixture. However, it would not have been the type of segregation that is the mark of ASA in humans.
In a different study, in 1997, Wisniewski and Hulse investigated the abilities of starlings to discriminate between individual starlings on the basis of their songs. After learning to distinguish between 10 recordings of the songs of starling A and 10 coming from starling B (each recorded in isolation) , the authors showed that the birds were still capable of this discrimination when the song of each bird was heard in the presence of a song from a third starling, C. Furthermore, they could still discriminate A’s song from B’s with greater-than-chance accuracy when the songs of four other starlings were added in the background. It certainly looks as though the starlings could truly segregate the individual bird songs, at least to some degree.
Analytic studies using tones
These results indicate that some sort of ASA is achieved by starlings, but is it similar to the ASA of humans? To find out, MacDougall-Shackleton, Hulse, T.Q. Gentner, and W. White, in 1998, asked whether European starlings could segregate a pattern of pure tones in the way people do. As a test stimulus, they used the pattern, ABA-ABA-ABA..., where A and B are pure tones of different frequencies and the hyphens represent gaps of the duration of a single tone. If the A and B tones together are perceived as a single perceptual stream a "galloping" (triplet) rhythm is perceived by humans. If two perceptual streams are formed, one composed of the A tones only, the other of the B tones only, a human will hear two sequences of tones that are isochronous (equally spaced in time), a faster one formed of the A tones (A-A-A-A- …) and a slower one formed of the B tones (B---B---B--- …).
Using sequences in which the tones were all of the same frequency (X), the birds were trained to peck one key (say the left one) if the X's were presented in a galloping rhythm (XXX-XXX-XXX-…) and the other key (say the right one) if it was presented in an isochronous rhythm, i.e., either the fast one (X-X-X-X-…) or the slow one (X---X---X--- …).
Then sequences containing two frequencies were presented (ABA-ABA-ABA-...), varying the frequency difference (Δ) between A and B. As Δ increased from 50 Hz to above 3500 Hz, the starlings’ choices of key increasingly indicated that they had segregated the high and low tones.
So the ability of starlings to segregate interleaved sounds is not restricted to bird songs, but can occur with arbitrarily chosen stimuli, and the segregation exhibits the same pattern as is observed in humans. It is likely therefore that the starling’s ability to distinguish a particular member of a mixture of birdsongs is at least partly based on a general process of perception that is shared with humans.
Goldfish
Birds are not the only animals that exhibit ASA in their auditory perception. In 1998, Richard R.. Fay classically conditioned goldfish to respond to a mixture of two sequences of sounds: high-pitched tones pulsed at a fast rate, and low-pitched tones pulsed at a slow rate. After this training the goldfish would respond to either of these types of sequence presented individually, but not to other sequences that resembled them, such as high-pitched tones pulsed at a slow rate. So it was not simply a particular pitch or tone rate that triggered the fish’s response during the tests, but only the actual sequences that had been present in the mixture to which they had been conditioned.
Subsequent research on goldfish by Fay in 2000 showed that, just as in humans, the segregation becomes stronger as the frequency separation of the intermixed sounds increases. Fay concluded that, “Thus, we are fairly confident in believing that goldfish, and fishes in general, are capable of sound source segregation, as we understand it for human listeners.… Therefore, scene analysis and source segregation are phenomena of biological interest and significance that can be studied in a comparative and evolutionary context.”
ASA in other animals
ASA has been observed using behavioral methods in other kinds of animals, including frogs (by Georg M.. Klump and H.Carl Gerhardt in 1992, bats (by Cynthia F. Moss and Annemarie Surlykke in 2001), and monkeys (by Akihiro Izumi in 2002).
Cortical measurement
The existence of ASA in non-human animals has made it possible to study the brain processes involved. Laboratory studies have made use of the phenomenon of stream segregation, in which a sequence formed of the alternation of two tones of different frequencies, A and B, can be heard either as a single sequence involving both the A and the B tones or as two separate sequences, each containing only one of the tones. This type of study has used monkeys and birds as subjects.
A careful and comprehensive study of responses from neurons in area A1 of the auditory cortex of awake macaque monkeys was carried out by Yonatan I. Fishman, Joseph C. Arezzo, and Mitchell Steinschneider in 2004 as a follow-up of a simpler pioneering study by Fishman and David H. Reser in 1999. The more comprehensive study alternated two tones of different frequencies at various frequency separations and various tone presentation rates and tone durations. One should note that area A1 of the auditory cortex is "tuned". Different parts of it respond most strongly to different frequencies, each part "preferring" a different frequency. A recording site in the auditory cortex was selected, and its "preferred frequency" was determined. Tone A was set to this frequency while that of B was displaced from it by different amounts during the course of the experiment. Since tone A was always at the "preferred frequency" of the recording site, the recorded activity was always higher in response to A tones; but there was a lesser response to B tones as well. However, whenever ΔF, tone rate or duration was changed in a direction that would lead to more reports of stream segregation in a human perceptual experiment, the response to B tones was reduced; i.e., the cortical site increased its preference for A tones. Presumably if the recording had been made at the site that responded best to the B tone, the changes in the stimulus variables would have caused a reduction of its response to the A tone. This increase in preference for the "best-frequency" tone, was interpreted as one of the brain mechanisms responsible for auditory stream segregation.
A similar experiment was performed by Mark A. Bee and Georg M. Klump in 2005, who recorded electrical activity in the forebrain of the European starling. As a stimulus, they used the galloping pattern, ABA-ABA-ABA-… , where A and B are tones of different frequencies. Under certain conditions, this sequence segregates into two streams. When segregation occurs, the triplet rhythm is replaced by two isochronous rhythms, a faster one involving the A tones (A-A-A-A-A-….), and a slower one involving the B tones (B---B---B---B---…). This simple change in rhythm makes it easy for a human or animal subject in a perception experiment to tell when segregation has occurred, and also makes it easy for a neuroscience researcher to decide whether a particular part of the brain is tracking the global signal (yielding a triplet rhythm in the recording from the brain site) or tracking the separate streams (yielding isochronous rhythms). The researchers reported that increasing the frequency difference, ΔF, between the A and B tones caused a reduction of the response to B at the brain site which "preferred" A. Also, manipulations of the interstimulus interval and the tone duration, in directions that should promote stream segregation, caused the preference of brain regions for their own best frequency to increase. Again this was interpreted as a mechanism underlying stream segregation.
Similar results have been found in the brains of mustached bats by Jagmeet S. Kanwal and colleagues in 2003.
Two aspects of brain function have been suggested as underlying these effects: (1) the fact that there are auditory regions of the vertebrate brain that are frequency-selective; and (2) there are processes of forward masking which suppress "off-frequency" tones more as the sequence speeds up. However, this can't be the whole story. For example, A and B tones can form separate streams on the basis of differences in timbre, even though they involve the same range of frequencies. They can also be segregated on the basis of spatial location. Yet a promoter of this two-mechanism theory could reply that there could be other neuron networks, each tuned to a different feature of the signal (such as spatial location, or spectral shape), which could substitute for the frequency-selective neurons in part 1 of the above argument.
However, there are stronger reasons for being skeptical of the sufficiency of the two-mechanism theory (tuning to a feature and forward masking) as an adequate account of stream segregation.
- In a realistic auditory scene, more than two frequency components are present, and the grouping is competitive. The choice made by the brain of whether to group A with B, with C, or with D depends on the relative strengths of the various acoustic relationships among all the frequency components that are present. Various similarities can compete with or strengthen one another in determining a grouping.
- Simultaneous grouping can compete with sequential grouping and vice-versa.
- Attention and other top-down processes can affect the grouping.
The ASA system is quite complex and requires that the parts of the brain that are specialized for the pick-up of specific types of information must work together to accomplish their job: grouping the perceptual input into representations of distinct sources of environmental sound. While it is interesting to find collections of neurons in the brain that seem to reflect aspects of stream segregation, any assertion that these neurons are responsible, in and of themselves, for the organization of streams, is surely a gross oversimplification.
